|
|
# Tutorial on NUMA issues on AMD K10 machines (Istanbul/Magny Cours)
|
|
# Tutorial on NUMA issues on AMD K10 machines (Istanbul/Magny Cours)
|
|
|
|
|
|
|
|
# Introduction
|
|
# Introduction
|
|
|
|
Almost all recent x86 systems embody a NUMA (non-uniform memory access) architecture. This means, that each CPU socket has locally attached memory with a low latency and high throughput while the sockets are interconnected by some network (HyperTransport used by AMD® and Quick Path Interconnect used by Intel®). If one CPU needs data that resides in another socket's memory, the data is read from the remote memory and transferred over the socket interconnect to the local CPU. Since this transfer requires 2 hops, it is slower than accessing the locally attached memory with only a single hop.
|
|
|
|
|
|
|
|
Add your content here.
|
|
In order to squeeze maximal performance out of a NUMA system with an application, it is important to know the system's architecture and the impact of accessing remote memory to the application runtime. The following tutorial gives insight about getting these information with the help of LIKWID.
|
|
|
|
|
|
|
|
|
|
|
|
|
# Test machine
|
|
# Test machine
|
| ... | @@ -134,10 +135,10 @@ Socket 1: |
... | @@ -134,10 +135,10 @@ Socket 1: |
|
|
|
|
|
|
|
# Node bandwidth map
|
|
# Node bandwidth map
|
|
|
|
|
|
|
|
With likwid-bench you can easily measure the bandwidth topology of a node. Above output
|
|
With `likwid-bench` you can easily measure the bandwidth topology of a node. Above output
|
|
|
already tells us that the machine has four NUMA domains, two on each socket.
|
|
already tells us that the machine has four NUMA domains, two on each socket.
|
|
|
|
|
|
|
|
The Numa domains are:
|
|
The NUMA domains are:
|
|
|
|
|
|
|
|
```
|
|
```
|
|
|
Domain 0:
|
|
Domain 0:
|
| ... | @@ -153,16 +154,15 @@ Domain 3: |
... | @@ -153,16 +154,15 @@ Domain 3: |
|
|
Processors: 1 3 5 7
|
|
Processors: 1 3 5 7
|
|
|
```
|
|
```
|
|
|
|
|
|
|
|
The following results were generated with the `copy_mem` benchmarks which is a assembly memcpy using non temporal stores. This causes that the caches are more or less bypassed.
|
|
The following results were generated with the `copy_mem` benchmarks which is a assembly `memcpy` using non-temporal stores. This causes that the caches are more or less bypassed.
|
|
|
All loads are directly to L1 cache and also the stores go via WC buffers to main memory.
|
|
All loads are directly to L1 cache and also the stores go via WC buffers to main memory.
|
|
|
The benchmark runs use likwid-bench as follows:
|
|
The benchmark runs use `likwid-bench` as follows:
|
|
|
```
|
|
```
|
|
|
likwid-bench -t copy_mem -g 1 -i 50 -w M0:1GB-0:M2,1:M2
|
|
likwid-bench -t copy_mem -g 1 -i 50 -w M0:1GB-0:M2,1:M2
|
|
|
```
|
|
```
|
|
|
|
|
|
|
|
Above example will place threads (all cores on a socket per default results in four) in the Memory domain 0, then for each stream the data placement can be specified. In this example both streams are placed in the memory domain 2. By that all combinations can be tested.
|
|
Above example will place threads (all cores on a socket per default results in four) in the Memory domain 0, then for each stream the data placement can be specified. In this example both streams are placed in the memory domain 2. By that all combinations can be tested.
|
|
|
|
|
|
|
|
|
|
|
|
|
<table>
|
|
<table>
|
|
|
<tr><td>**NODE**</td><td>0</td><td>1</td><td>2</td><td>3</td></tr>
|
|
<tr><td>**NODE**</td><td>0</td><td>1</td><td>2</td><td>3</td></tr>
|
|
|
<tr><td>0</td><td>12163</td><td>7279</td><td>7590</td><td>5831</td></tr>
|
|
<tr><td>0</td><td>12163</td><td>7279</td><td>7590</td><td>5831</td></tr>
|
| ... | @@ -171,18 +171,20 @@ Above example will place threads (all cores on a socket per default results in f |
... | @@ -171,18 +171,20 @@ Above example will place threads (all cores on a socket per default results in f |
|
|
<tr><td>3</td><td>5759</td><td>7404</td><td>7490</td><td>12570</td></tr>
|
|
<tr><td>3</td><td>5759</td><td>7404</td><td>7490</td><td>12570</td></tr>
|
|
|
</table>
|
|
</table>
|
|
|
|
|
|
|
|
|
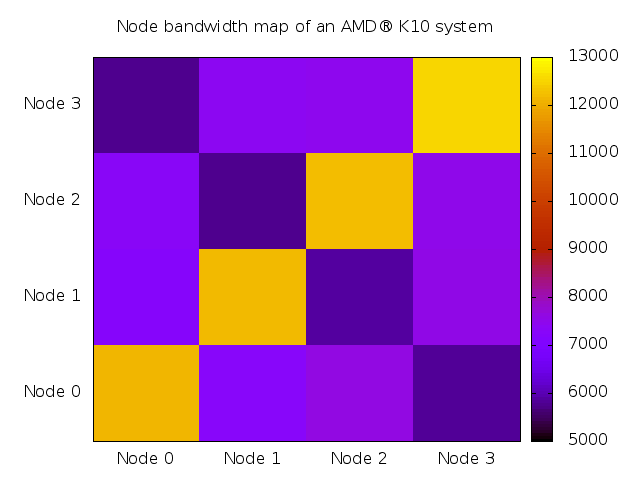
|
|
|
|
|
|
|
You can roughly separate 3 different access domains: local DRAM (ca. 12GB/s), horizontal/vertical connections (7 - 7.5 GB/s) and cross connections (ca. 5.8 GB/s).
|
|
You can roughly separate 3 different access domains: local DRAM (ca. 12GB/s), horizontal/vertical connections (7 - 7.5 GB/s) and cross connections (ca. 5.8 GB/s).
|
|
|
While you can measure a difference between the stronger connected link on the same socket and the vertical link between sockets, the difference in our measurements is not very large.
|
|
While you can measure a difference between the stronger connected link on the same socket and the vertical link between sockets, the difference in our measurements is not very large.
|
|
|
|
|
|
|
|
# Detect Numa problems in threaded codes
|
|
# Detect NUMA problems in threaded codes
|
|
|
|
|
|
|
|
likwid-perfctr offers a performance group NUMA on K10 based architectures. This group measures the requests (read/write) from the local NUMA node to all other NUMA nodes.
|
|
`likwid-perfctr` offers a performance group NUMA on K10 based architectures. This group measures the requests (read/write) from the local NUMA node to all other NUMA nodes.
|
|
|
```
|
|
```
|
|
|
likwid-perfctr -c 0,8,1,9 -g NUMA sleep 10
|
|
likwid-perfctr -c 0,8,1,9 -g NUMA sleep 10
|
|
|
```
|
|
```
|
|
|
This call will measure the traffic between NUMA nodes on one core in each memory domain for 10 sec. . It is interesting that on this MagnyCours machine there is a constant traffic from all nodes to node 0. This was e.g. not the case on a IStanbul two socket system tested.
|
|
This call will measure the traffic between NUMA nodes on one core in each memory domain for 10 sec. It is interesting that on this MagnyCours machine there is a constant traffic from all nodes to node 0. This was e.g. not the case on a Istanbul two socket system tested.
|
|
|
|
|
|
|
|
Ideally every node should only have traffic with itself. The following example shows the likwid-perfctr output a threaded memcpy code with correct first touch memory allocation:
|
|
Ideally every node should only have traffic with itself. The following example shows the `likwid-perfctr` output a threaded `memcpy` code with correct first touch memory allocation:
|
|
|
|
|
|
|
|
```
|
|
```
|
|
|
./likwid-perfctr -c 0,8,1,9 -g NUMA ./likwid-bench -t copy_mem -i 50 -g 2 -w M1:1GB -w M2:1GB
|
|
./likwid-perfctr -c 0,8,1,9 -g NUMA ./likwid-bench -t copy_mem -i 50 -g 2 -w M1:1GB -w M2:1GB
|
| ... | | ... | |